任何一个问题都是一类问题
内存管理
数据结构
树
- 树的迭代方式:不论是Linux中的PCB还是CSS中的选择器或者是MySQL中的B+树,都可以抽象为树形结构,而且都提供了:父节点指针、子节点指针、兄弟节点指针这三种访问方式
调度问题
调度问题有两类:第一类是n个人放到m个队列上,第二类是n个人抢1个坑
第一类:
- 多核CPU多队列调度策略:为每个CPU维护一个待执行队列
- GO语言的GMP模型:为每个系统级线程P维护一个待执行队列freeG
- CDN调度算法:n个人访问m台机器,每台机器有处理的阈值,问怎么分配(最大流)
需要注意的问题
- 负载不均衡的情况怎么处理?是让每个队列去别的队列抢人吗?(GMP)还是维护一个全局的调度器?(CPU)
第二类:
- 线程的调度策略:FIFO/CFS。(JVM是直接把Thread的调度托管给OS做)
- GMP中P决定将哪个G绑定到M上(每个运行不超过10MS)
- VMThread以VMOperate链表的形式link起来(但是没搞明白调度算法是什么)
需要注意的是:当引入调度问题的时候,实际上引入了两个问题
- 选哪个:即从n个目标当中选哪个的问题
- 如何切换:当该目标执行完成之后,如何把它放回原处,或者说不等它执行完成就把他放回原处
现在在思考的一个问题:
如何手写一个用户态的线程?
维护好每个线程的栈空间以及PC,线程切换的时候不由内核态介入,而直接把数据保存在栈空间中。
以及设计好线程的调度算法
从系统架构来看程序
日志系统
我认为的日志:从最基本的程序的print到大型日志的log,只要是能打印出程序运行过程中内部的变量的取值的txt文档或者文件,都能被称作是日志。
常见的有
MySQL中的binlog作为SQL层的日志
Postgres中的redolog/WAL作为Engine层的日志
大型项目中一般会有log库,且用这些log库打出来的日志有唯一的id,各个微服务使用统一的log平台,并在log中传入context可以实现全链路的追踪
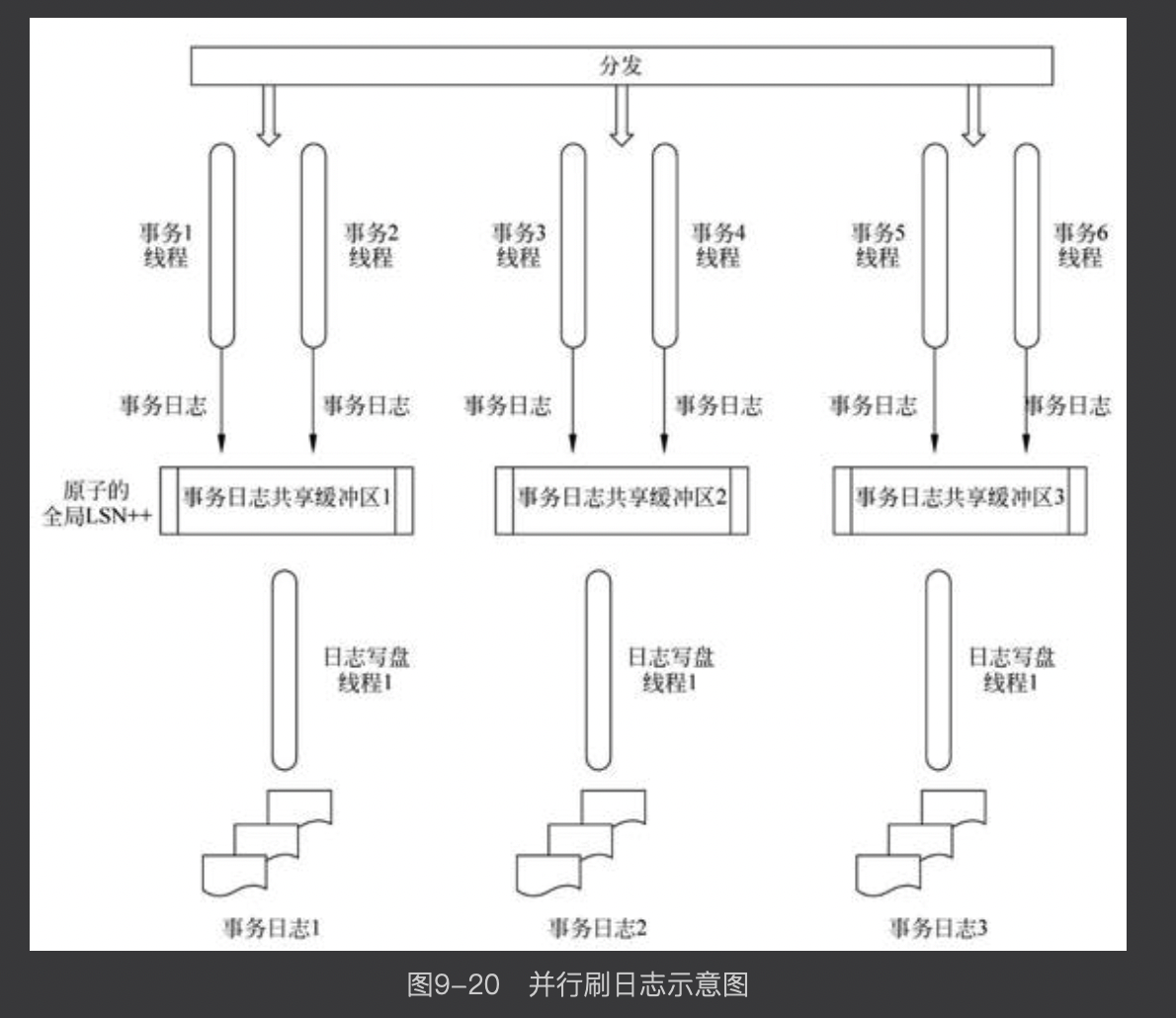
日志系统的常见技术手段
- 并行刷日志
监控系统/metrics系统
公共组件
- 线程管理
- 异常处理
- 基础工具类
测试
- SpringBoot提供了Test类来进行测试
- ClickHouse这种的会有一个单独的test文件夹,里面放了各种sql语句,在CI/CD的过程中进行测试
权限系统
对于大型系统,一般都会有多租户机制,即对于不同用户的不同权限分配。
权限校验一般会放在最开始的部分,不与具体业务耦合。
a. Linux系统有用户和用户组的概念
b. Vue前端可以做到按钮级别的权限管理
c. SpringBoot可以使用Security来做到方法级别的权限管理(RBAC权限模型)
d. MySQL等数据库可以做到表的CRUD权限管理- 配置文件
例如Java的applicaiton.properties
1 | spring.datasource.driver-class-name=com.mysql.jdbc.Driver |
堆栈与内存信息
阅读源码的时候可以使用printTrace之类的打印函数调用堆栈,同时若打印出的堆栈是xxx.so文件,可以使用objdump反编译
API设计
- 一个好的traffic cop应该怎么设计?
任何一个大型项目(openGauss)和大的模块(JVM JIT)其主线流程一定可以被拆解为几个小的模块。
以C1 JIT为例,无非就是
1 | setup, // 1)设置C1编译环境 |
但是main函数该怎么设计呢?
一种思路是setup -> build -> emit_lir -> codemit -> codeinstall,从头调用到尾
还有一种思路就是顺序调用
1 | call setup |
那么显然后者的设计更加清晰,能够让阅读代码的人一眼就看出,这个大的模块被拆成了几部。
- API的数量与参数的个数之间的trade off
原则上是能以参数提供就不要增加API数量
系统设计
HINT:MySQL读写认为是3000,Redis认为是10W
- 抖音关注系统设计:支持查询粉丝,查询关注的人
数据库<id, 关注者, 被关注者>
查询粉丝Where 被关注者 = A
查询关注的人Where 关注者 = A
对于热A,采用Redis缓存机制
- Feed流系统设计
什么是Feed流系统:
定义Feed = {feed_id, author_id, time, data}
有n个人,和m条关注关系(即A->B表示A关注了B, 默认A->A存在),且每个人都有自己的vector<Feed>
有k次操作,每个操作有3种类型op
op=1:输入author_id,输出一个vector<Feed>,为author_id关注的所有人的vector数据按time排序之后的并
op=2:输入A, B,表示A关注了B
op=3:输入author_id, post_id, new_data,找到Feed中对应的post_id,并把data改为new_data(time不变)
数据范围\(n=10^8\), \(m=10^12\)(假设每个人关注1000个用户), 每个人发布了1000条Feed
做法:
- 暴力
维护两张表,第一个是关注表<id, A, b>,第二个是Feed表<feed_id, author_id, time, data>
对于op=1,查询的时候先查询A关注了谁,得到List<B>, 再查出所有的Feed,并按时间排序。
复杂度,对于单词查询为1000 * 1000 / 3000 = 333s
- 优化
做一层缓存,将热Feed丢到Redis中。